Short answer: Capacity planning for scaled agile in a large agency means rolling each team’s real, individually calculated capacity — past velocity minus days-off minus partial allocations — up into one program-level view before the program commits to a quarter or a release. Plan each team bottom-up, reconcile dependencies and shared people across teams, then commit to what the slowest dependency actually allows, not to the sum of everyone’s best-case math.
If you run a program with five, ten, or twenty teams under one mission, you already know the failure mode. Every team plans its own sprint, every team looks fine in isolation, and the program still misses the fiscal-year milestone. The problem isn’t any single team — it’s that no one reconciled capacity across teams before the commitment went up the chain. With workforce reductions and flat budgets pushing agencies toward “fewer people, same mission,” that reconciliation gap is now where large programs quietly bleed schedule.
Why does multi-team capacity planning fail in large agencies?
At a single-team level, capacity planning is tractable: you know your people, their days off, and roughly how many points the team has historically finished. At program scale, three things break that simplicity.
First, shared people. One senior engineer or one security reviewer is often split across three teams. Each team plans as if it has that person, so the program double- or triple-counts the same capacity. Second, cross-team dependencies. Team B can’t start until Team A ships an interface, so Team A’s slippage silently consumes Team B’s sprint. Third, inconsistent units. If each team estimates differently and no one normalizes, the program-level “total points” number is meaningless — you can’t add Team A’s points to Team C’s and forecast anything real.
The fix isn’t a heroic spreadsheet. It’s a repeatable, bottom-up planning discipline where every team produces an honest capacity number the same way, and the program reconciles those numbers before committing.
How do you calculate capacity across multiple teams?
Use a five-step framework. The first two steps happen inside each team; the last three happen at the program level.
- Calculate each team’s raw capacity bottom-up. Start from recent velocity (the average points finished over the last three to five sprints), then subtract days-off — PTO, federal holidays, training, detail assignments — converted into a capacity reduction. A team that historically finishes 40 points but is losing 20% of its person-days this sprint plans for roughly 32, not 40.
- Net out partial allocations. If a person is only 50% allocated to a team, count 50% of their availability. Do this per person, not as a vague team-level fudge factor — that’s where double-counting hides.
- Resolve shared-people conflicts at the program level. List every person allocated to more than one team and confirm their splits add up to 100% or less. If three teams each claim 40% of one reviewer, someone is planning on capacity that doesn’t exist. Fix it before sprint planning, not during the demo.
- Map dependencies and sequence the commitment. Identify which teams block which. A program can only commit to the throughput its critical-dependency chain allows. If Team A is the bottleneck, the program’s realistic output is gated by Team A’s capacity, regardless of how much slack Teams B through E have.
- Commit the program to the reconciled number — and write down why. The output is a single program-level capacity figure, the allocation decisions behind it, and the dependency assumptions. That record is what you report up the chain and what you revisit when something slips.
A worked example
Say a State digital-services program runs four teams ahead of a September fiscal-year release. Bottom-up, the teams report raw velocities of 38, 42, 30, and 25 points — a tempting program “total” of 135.
Now apply the reconciliation. Team 3 is losing two of its six people to a four-week training detail, dropping its realistic capacity from 30 to about 20. One security reviewer is shared across Teams 1, 2, and 4; each had quietly planned as if they owned 100% of her time, but she’s actually 40/30/30 split — so each of those teams loses roughly a sprint-day of review throughput, trimming a few points each. And Team 4 can’t integrate until Team 1 ships an authentication service in the same sprint, making Team 1 the critical-path bottleneck.
After reconciliation, the honest program commitment is closer to 112 points, not 135 — and it’s sequenced so Team 1’s authentication work lands first. The 23-point gap is exactly the overcommitment that would otherwise have surfaced as a missed September milestone and an uncomfortable conversation with leadership. Surfacing it in planning turns a delivery surprise into a scope decision you make on purpose.
Why doing this inside Jira makes it repeatable
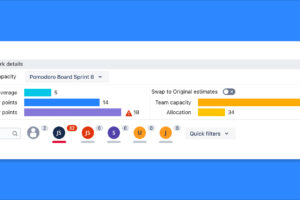
The reconciliation above is real work, and if it lives in a stack of disconnected spreadsheets it happens once, imperfectly, and never gets revisited. Doing it on one screen inside the Jira backlog — where the teams, the past velocity, the days-off, and the per-person allocations already live — is what makes it repeatable quarter after quarter. For agencies modernizing onto Atlassian Cloud, including Atlassian Government Cloud (AGC), keeping planning in the same place as the work is part of the move off spreadsheets and toward a single source of truth.
Sprint planning with Capacity Planning for Jira lets each team see velocity, days-off, and allocation on one screen before committing, inside the backlog they already use. It’s Cloud Fortified and runs on Atlassian’s SOC 2 Type II / ISO 27001 platform. Just as useful for a multi-team program: because every capacity decision is made and recorded in the tool — who was allocated, what days-off were subtracted, why the team committed to N points — you get a documentation trail of how the commitment was reached. In a public-sector world that increasingly rewards being able to prove what happened, who acted, and what evidence supports a decision, that planning record is worth as much as the plan itself. (The app records planning decisions; it is not a compliance product and does not provide any certification.)
FAQ
How is capacity planning different for scaled agile versus a single team? The core math is the same per team, but at scale you add a reconciliation layer: resolving people shared across teams, sequencing cross-team dependencies, and rolling individual capacity into one program number. The program commits to the reconciled figure, not the sum of best-case team estimates.
How do we handle one specialist shared across several teams? Count that person’s allocation per team as a percentage and confirm the percentages total 100% or less across all teams. If they over-total, the program is planning on capacity that doesn’t exist — adjust before teams lock their sprints.
Does this app make our agency SOC 2 or FedRAMP compliant? No. The app is Cloud Fortified and runs on Atlassian’s SOC 2 Type II / ISO 27001 platform, but it provides no certification of its own and is not a compliance product. It helps you document planning decisions; compliance outcomes remain yours and Atlassian’s to manage.
Try it: Install free · Help docs

Leave a Reply
Your email is safe with us.